La dernière Intelligence artificielle de Google peut comprendre un livre
Il ne suffisait pas de numériser des millions d’ouvrages avec Google Books : la machine devait encore les assimiler, et pouvoir exploiter cette somme de données. En matière de machine learning, Google continue sans cesse d’améliorer ses robots. Pour 16 Go — une grosse clef USB — son dernier produit peut comprendre un livre d’un million de lignes.

À moi les romans de Stephen King ! - pixabay licence
Comprendre. Autrement dit, lire en prenant conscience de ce qui est écrit, en assimilant les informations communiquées, avec un sens de la narration. La prochaine étape consistera à donner des capacités de jugement esthétique aux œuvres, certainement.
Or, le plus important défi pour une IA travaillant sur le langage, c’est de parvenir à saisir le contexte du livre qu’elle ingurgite. Pour résoudre ce problème, les techniciens de Google ont mis au point Reformer.
Ce dernier est l’héritier de Transformer, un réseau neuronal qui compare les mots à l’intérieur d’un paragraphe, pour établir les relations entre eux. Reformer va plus loin : si ses concurrents peuvent comprendre quelques lignes, voire des paragraphes, ils ont besoin d’importantes ressources numériques.
Des groupes de mots
Transformer, par exemple, use d’un grand espace de stockage, pour seulement traiter quelques milliers de mots. Pour un livre, la chose devient insoluble. Reformer, lui, repose sur un nouveau modèle : le locality-sensitive-hashing. Il s’agit d’une méthode mathématique « de recherche approximative dans des espaces de grande dimension », indique Wikipedia. On n’est guère plus avancé.
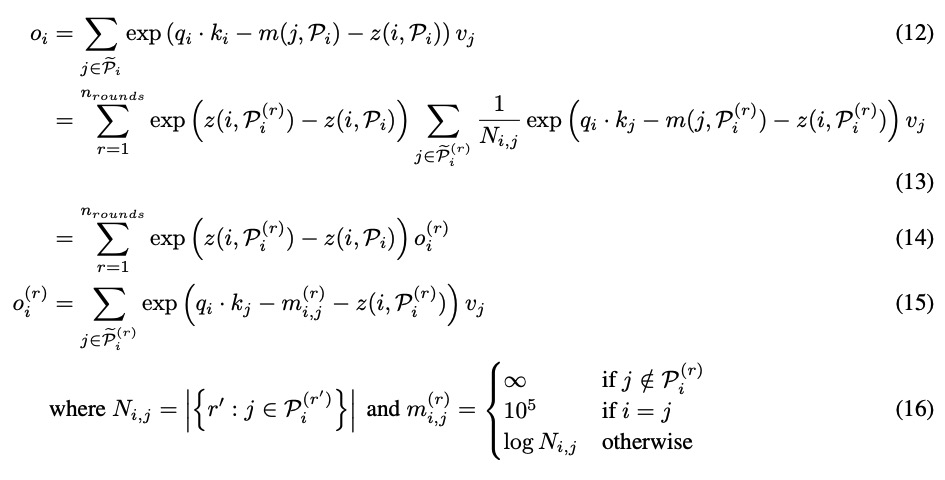
Reformer en pleine lecture...
Les scientifiques ont recours à cette approche pour la comparaison de séquences ADN, par exemple, ou dans la traque de similarités entre différents fichiers audio. Dans le traitement automatique du langage naturel, cette solution imite la compréhension des mots par les humains, tout en favorisant le traitement de grandes quantités de données.
Comment cela fonctionne pour Reformer ? Eh bien, au lieu de comparer les mots entre eux, il va hacher le texte, pour établir des listes de champs lexicaux. Une fois un groupe lexical établi, un premier traitement intervient, d’analyse des vocables retenus. Par la suite, les confrontations s’opèrent entre groupes de mots, réduisant considérablement les délais et les besoins de stockage.
Et la conclusion des ingénieurs de Google est que Reformer se trouve en mesure de traiter des livres entiers – un petit miracle pour le text and data mining, évidemment. Le code source a été mis en ligne, à cette adresse pour les joueurs. Et le détail de ce projet est ici.
Dossier —L’intelligence artificielle au service du livre et de la lecture
Plus d'articles sur le même thème



































Autres articles de la rubrique Métiers




































Commenter cet article