Numérisation : l'OCR Google Books change des 'bras' en 'anus'
Les êtres humains ont encore de beaux jours devant eux, lorsqu'il s'agit de la numérisation de livres. Transformer un ouvrage papier en version numérique peut avoir de fâcheuses conséquences, lorsque l'on se repose entièrement sur une machine. La Reconnaissance Optique de Caractères, ou OCR, dans le jargon, fait parfois des boulettes colossales, aboutissant à des fous rires violents…

Un scanner de livres
ActuaLitté, CC BY SA 2.0
Bibliothèques, éditeurs, etc., aujourd'hui, différents maillons de la chaîne du livre se lancent dans la numérisation. Il suffit finalement d'un scanner, de photographier les pages, et de confier ensuite les fichiers à un logiciel, qui va s'occuper de transformer les images en texte. Sauf qu'en l'absence de relecture humaine, il peut rester quelques couilles, au sens quasi propre.
Google Books, dont les scanners sont souvent mis en cause dans ce genre d'histoire, va en avoir les bras qui tombent, littéralement. Plusieurs titres numérisés contenant le mot ‘arms', les bras, n'ont pas été correctement retranscrits, et voilà que le mot s'est changé en ‘anus'. Effectivement, une certaine proximité graphique, particulièrement dans des ouvrages anciens, peut expliquer l'erreur, mais n'a pas manqué d'attirer l'attention.
En clair, plus le texte est ancien, plus les robots OCR de Google ont tendance à reconnaître le mot ‘anus' et non le mot ‘arms', constate le Guardian. Et de citer plusieurs exemples assez cocasses :
So if the text is old, and it says "arms," the OCR scanner will see it as "anus." OMG. pic.twitter.com/DMQ4kBDLqE
— Sarah Wendell (@SmartBitches) 30 Avril 2014
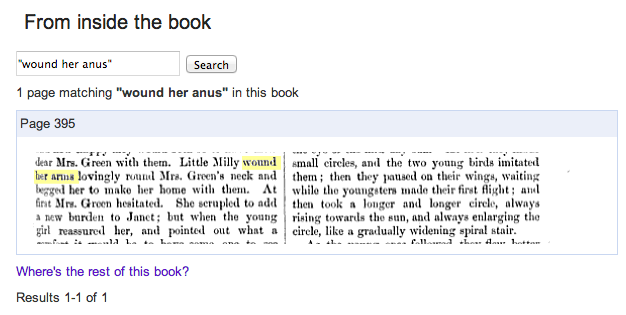
Et finalement, la phrase innocente « She put her arms around his neck », se change en une incongruité, « She put her anus around his neck ». De passer ses bras autour du cou de quelqu'un, à passer son anus autour, on s'interroge sur l'élasticité du corps humain… Comme les exemples se multiplient, on en conclut rapidement que finalement, c'est Google qui doit avoir les idées mal placées ? Car parfois, les choses deviennent particulièrement complexes : « Little Milly wound her anus lovingly around Mrs Green's neck and begged her to make her home with them. At first Mrs Green hesitated. » (voir sur Google Books)
Little Milly enroula amoureusement son anus autour du cou de Mme Green, et la pria de venir à la maison avec eux. Tout d'abord, Mrs Green hésita.
On peut comprendre que l'hésitation soit motivée. Mais maintenant que le problème est soulevé, il ne reste plus à Google qu'à se sortir les doigts du bras ?
On renverra également l'information aux responsables du projet ReLIRE, projet de numérisation des oeuvres sous droit indisponibles, du XXe siècle. Ces derniers ont assuré qu'une fois les oeuvres numérisées, il n'y aurait pas de relecture, simplement parce qu'il n'y avait pas de budget débloqué pour ce faire. Or, les critères de numérisation, intenables sans l'intervention d'une relecture humaine, nous assurait un spécialiste, serait de 99,99 % de taux de reconnaissance, « soit 1 caractère erroné maximum tous les 10.000 caractères ».
« Une erreur par page, sur un livre numérisé qui a déjà été édité, et qui a donc déjà été corrigé a priori (au XXe siècle, il y avait encore des correcteurs chez les éditeurs) ! Donc en fait, leur numérisation ne va pas laisser un mot erroné par page, mais va ajouter un mot erroné par page depuis un livre qui n'en contenait pas a priori », soulignait un éditeur numérique.
On songera aux auteurs qui, découvrant une erreur semblable à arms/anus, se diront qu'avec cette histoire de numérisation des oeuvres indisponibles, leurs craintes n'étaient pas… sans fondement ?
Plus d'articles sur le même thème




































Autres articles de la rubrique Médias





































Commenter cet article