reCAPTCHA : Si vous êtes un humain, il suffit de le dire à Google
Voilà bien longtemps, une société proposait de lutter contre les robots qui pullulent sur le net, en utilisant un système d'identification pour les humains. CAPTCHA était né, et grâce à d'étranges lettres, tordues, les internautes se faisaient reconnaître comme faits de chair et d'os. Et puis, vint le reCAPTCHA, qui intégra rapidement le giron de l'écurie Google. Un service qui va s'arrêter, dans la forme qu'on lui connaît.
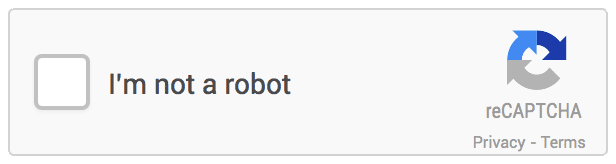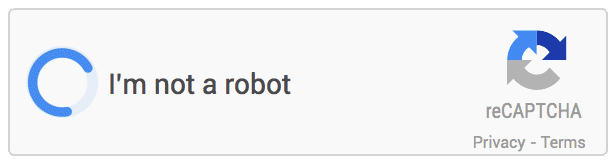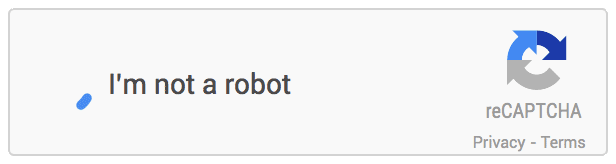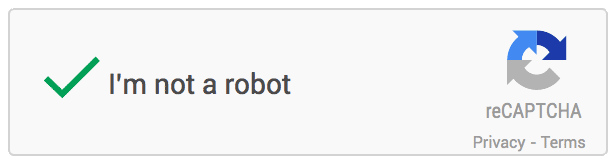
Dans un message officiel, Google explique que, durant des années, ils ont incité les utilisateurs à confirmer qu'ils n'étaient pas des robots, en se servant de cette solution de lettres et chiffres. « Mais nous avons pensé qu'il serait plus facile de demander simplement, et directement, à nos utilisateurs, s'ils sont ou non des robots – alors nous l'avons fait ! » Et voici ce que cela donne
Une toute nouvelle API est mise en place, par laquelle d'un simple clic, les identifications pourront s'opérer. Et si elle se présente sous une forme très primaire, la solution technique est en réalité particulièrement complexe. Comme le texte déformé n'est plus un test fiable, il faut arriver à de nouvelles procédures. Les humains n'auront plus qu'à cocher la case qui les identifie comme tels.
Cependant, le CAPTCHA ne disparaîtra pas totalement, et des variantes un peu plus complexes sont à l'étude. Avec notamment des solutions pour mobiles, inévitables alors qu'internet se joue de plus en plus sur la mobilité.

L'une des raisons pour lesquelles reCAPTCHA ne s'arrêtera certainement jamais, c'est aussi que Google s'en sert pour améliorer la numérisation des livres. En effet, les lettres, ou chiffres, présentés aux internautes, sont puisés dans les livres numérisés.
Conçu voilà 14 ans pour empêcher les ravages du spam dans les boîtes à courriel, reCAPTCHA a notablement évolué, pour aider notamment à transcrire les journaux et manuscrits aux lettres passablement déformées. En effet, les personnes vont scruter le mot affiché, proposer leur version et par recoupement, Captcha relaiera à un ordinateur le mot mystère. Cela aidait, en 2008, à la numérisation de 160 livres par jour. Combien aujourd'hui ?
D'ailleurs, Internet Archive envisageait, durant un temps, de mettre en place sa propre solution open-source, pour arriver aux mêmes fins. C'est en 2007 que reCAPTCHA remplacera le Completely Automated Public Turing test to tell Computers and Humans Apart, avec ces deux mots déformés, mis l'un à côté de l'autre. Mais les livres du domaine public, que numérise Google, quelle est l'utilisation marchande qui en est faite ?
Benjamin Sonntag, de la Quadrature du Net, nous en avait exposé le projet, dans ses grandes lignes. « On pourra savoir de quel livre vient le mot qui est utilisé pour la reconnaissance, disposer de données plus transparentes. On s'appuiera sur le logiciel libre de reconnaissance de caractère Tesseract, qui permet de pouvoir déterminer des termes dont on n'est pas certain. Mais également de donner l'emplacement du mot sur l'image. L'idée n'est pas de rendre ce logiciel plus intelligent, les algorithmes ne sont pas conçus pour cela, mais simplement d'offrir une alternative libre, par rapport à celle de Google. »
Et d'ajouter : « Une alternative, c'est de la concurrence, mais dans le domaine du livre, cela permet de rouvrir le jardin que Google avait fermé. Que font-ils de cet usage privatif des données liées à Google Books ? Ils assurent travailler pour le bien de l'humanité, mais, personnellement, je ne les crois pas. Avec notre outil, nous proposerons un système qui peut être modifié, et qui n'appartient pas à Google. Cette recherche d'ouverture est essentielle. »
Après, il restera toujours la méthode de Blade Runner, et la perception de l'empathie chez l'internaute, pour le différencier du réplicant...
Plus d'articles sur le même thème



































Autres articles de la rubrique Médias




































Commenter cet article