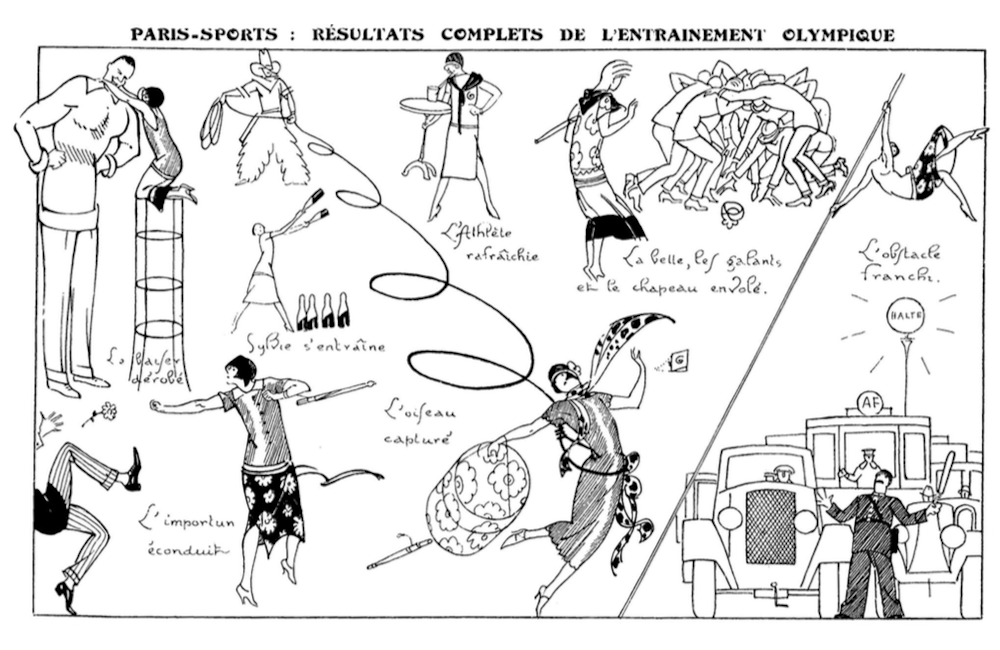
2,6 millions d'illustrations de livres, libres de droit sur Flickr
Parmi ses différentes missions, l'organisation Internet Archive a saisi à bras-le-corps les numérisations de livres, en récupérant les fichiers libres de droit auprès des bibliothèques pour les inclure à son gigantesque répertoire. Quelques 600 millions de pages, accessibles via un moteur de recherche dans le texte : aussi perfectionné soit-il, ce dernier laissait de côté les illustrations, très présentes dans ces ouvrages anciens.

Internet Archive fournissait bien les illustrations des différents ouvrages scannés, mais ces dernières, proposées au format JPG, et dépourvues de métadonnées, ne pouvaient pas être triées à partir d'un résultat de recherche. Conscient du problème, Kalev Leetaru, membre du comité de recherche de Yahoo ! à l'université de Georgetown, a créé un programme qui fournit des métadonnées aux images avant de les uploader sur Flickr, le service de Yahoo ! pour le partage de photographies.
« Pendant toutes ces années, les bibliothèques ont numérisé leurs collections, mais les ont converties en fichiers PDF ou en documents dotés d'une recherche dans le texte. Elles se sont concentrées sur les livres en tant qu'objet textuel », explique Kalev Leetaru, qui met le doigt sur un point essentiel du patrimoine. Difficile, en effet, d'imaginer un traité scientifique ou une étude architecturale sans illustrations, sans parler des œuvres musicales.
Le programme créé par Kalev Leetaru repère les images des scans, qu'il isole au format JPEG, avant de récolter des métadonnées à l'aide du titre du livre, de l'auteur, de l'éditeur, mais aussi du texte environnant l'image ou de la légende.
Pour le moment, ce sont quelque 2,6 millions d'images qui ont été mises en ligne sur le compte Flickr Internet Archive Book Images, en attendant les 12 millions, au total, disponibles dans les livres publiés entre 1500 et 1922. Bien entendu, elles font toutes partie du domaine public, et peuvent être utilisées à tort et à travers – mais en toute légalité.
Leetaru espère que Wikipédia s'emparera des images pour enrichir ses propres articles, mais il invite également toutes les bibliothèques autour du monde à utiliser son programme sur leur propre collection, afin d'augmenter la base de ressources disponibles. Il travaillera également au perfectionnement de son programme, qui montre quelques ratés dans le rendu des métadonnées. Toutefois, il reste très impressionnant pour nombre de professionnels de l'information, puisqu'il indique notamment le titre exact de l'ouvrage et le lien pour accéder au titre complet sur Internet Archive.
Même si elle ne propose pas encore 12 millions d'images, la galerie de ActuaLitté est également en ligne sur le site de partage de photos Flickr, avec des images sous Creative Commons.
Plus d'articles sur le même thème


































Autres articles de la rubrique Métiers






































Commenter cet article