La plateforme Correct de la BnF : 'Tout l'enjeu réside dans le réseau'
Le projet est en développement depuis 2 ans, et a rassemblé 8 partenaires autour de la Bibliothèque nationale de France : la plateforme de correction participative de documents, Correct, est en bêta test depuis quelques jours. L'outil, qui se présente comme un réseau rassemblant les intéressés, est accessible à tous, pour que les utilisateurs s'emparent des documents de Gallica.

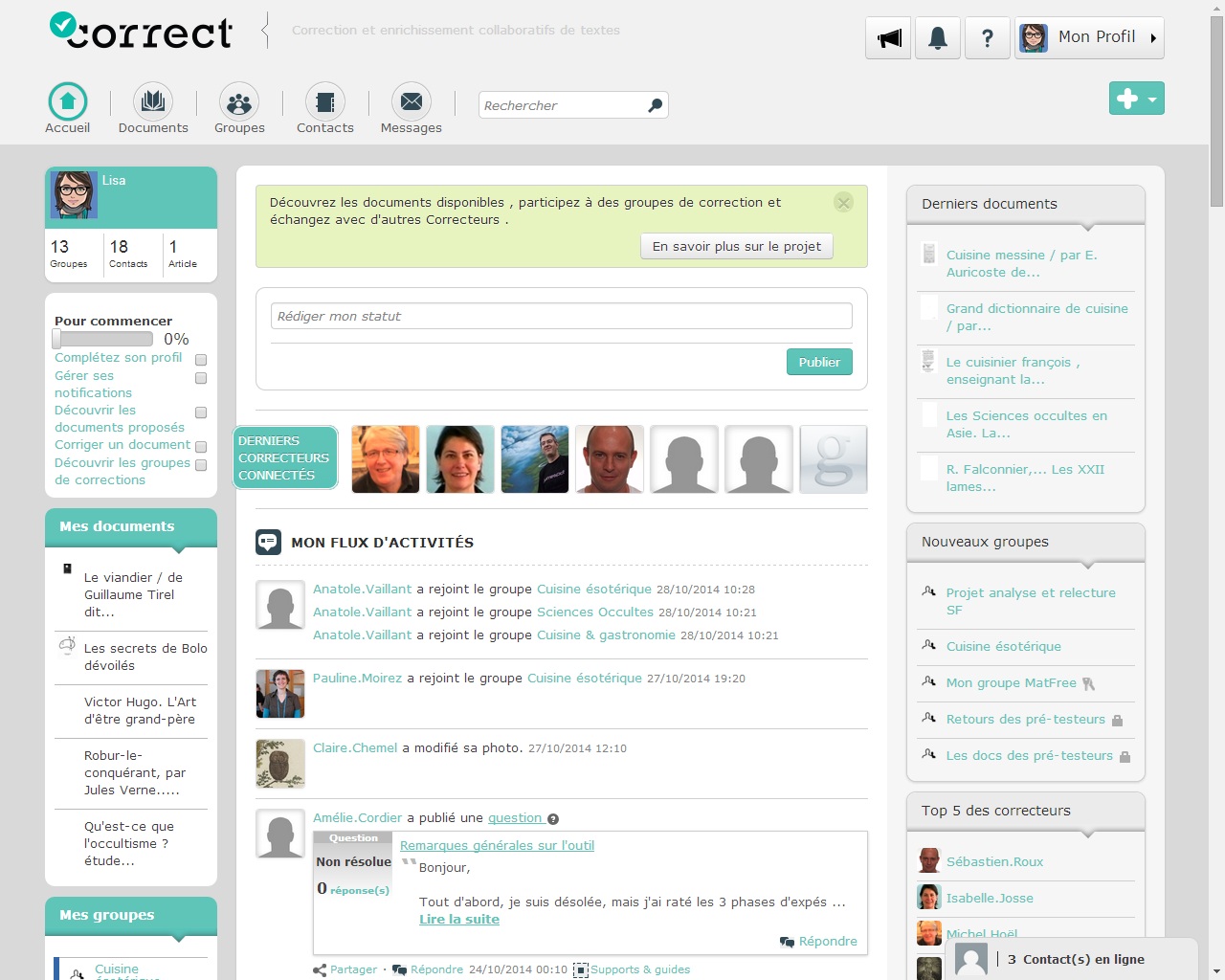
Capture d'écran du module de correction de la plateforme Correct
Pour le lancement de la plateforme, en phase bêta jusqu'en juin 2015, ce sont 57 documents en provenance de Gallica qui sont désormais accessibles par les utilisateurs, et qui peuvent être corrigés. Différentes collections ont été créées, pour inviter les premiers inscrits à choisir des documents en fonction de leurs centres d'intérêt : roman d'anticipation, contes d'ici et d'ailleurs, cuisine et gastronomie...
Pour le moment, les documents mis en ligne sont assez simples, et postérieurs à 1800, pour une phase de test qui s'articule autour de thématiques fortes et accessibles : les sciences occultes ont ainsi été choisies, car elles font partie des catégories les plus consultées et téléchargées sur Gallica.
La correction participative de manuscrits est un outil utilisé par nombre d'institutions, à travers le monde : la bibliothèque nationale d'Australie a mis en place une initiative semblable, tout comme l'université de l'Iowa, depuis 2011.
La grande initiative de Correct réside dans son statut de réseau : « Tout l'enjeu est dans cette notion de réseau, qui permet à tous de corriger et de partager les documents avec d'autres personnes. Sur la plateforme de la Bibliothèque nationale d'Australie, le correcteur volontaire est seul, et nous prenons le pari que les communautés et les centres d'intérêt vont motiver la correction » souligne Isabelle Josse, chef du projet Correct à la BnF, au département de la conservation, numérisation et OCR.
Pour le moment, 214 personnes se sont inscrites, et 6 groupes de correction, selon les centres d'intérêt, ont été créés.
Améliorer les OCR et l'accessibilité de Gallica
La mise en ligne de Correct, après 2 années de développement impliquant Jamespot, Urbilog, i2S, ISEP, l'INSA de Lyon, l'Université Lyon 1 et l'Université Paris 8, vient renforcer la politique de numérisation et de valorisation de la Bibliothèque nationale de France, rappelle Arnaud Beaufort, directeur général adjoint de la BnF.
« En 1996, les documents numérisés étaient au format image, et l'OCR (Optical Character Recognition, reconnaissance optique de caractères) est arrivé en 2007 pour convertir toutes les numérisations au format texte. Il est appliqué sur tous les marchés de numérisation de la BnF, avec des plans de traitements rétrospectifs pour d'anciens documents numérisés », précise Arnaud Beaufort.
Le souci, c'est que les technologies d'OCR, y compris pour les documents imprimés, ne sont pas encore optimales : « Sur Gallica, dès que le taux d'OCR est supérieur à 60 %, nous rendons disponibles la version texte du document, mais certains documents n'en disposent pas, car la reconnaissance renvoie de trop mauvais résultats. »
La BnF avait déjà sollicité l'outil Wikisource, en avril 2010, pour l'aider à corriger l'OCR de 1400 textes, mais le réseau Correct va plus loin : un bouton de correction sera directement intégré à Gallica, dans les prochains mois, qui reverra l'usager sur Correct. À terme, ce sont donc tous les documents de Gallica, soit 3 millions de pages, qui seront concernés par l'outil.
De plus, les Orange Labs, service de recherche et développement liés au groupe de télécommunications, ont travaillé à un algorithme pour améliorer les documents ALTO de la BnF. Ces derniers sont des fichiers qui lient les transcriptions texte aux documents image, afin de permettre des actions comme le copier-coller, directement sur la page numérisée. « Il s'agit, pour faire simple, d'un document XML qui code à la fois le texte et la position de chaque caractère, avec les pixels correspondants », résume Arnaud Beaufort.
L'enjeu est plus important qu'il n'y paraît, notamment en terme d'accessibilité, via le moteur de recherche de Gallica ou d'autres, comme Google, mais aussi pour les chercheurs qui utilisent ces documents comme référence.
Un travail commun, et des usages à venir
L'autre innovation centrale de la plateforme Correct repose sur la propagation des corrections, et la méthode de vérification adoptée. « Chaque utilisateur de la plateforme travaille sur une épreuve du texte choisi qui lui est propre, et sur lequel il ne voit que ses corrections. Pour vérifier les apports, l'algorithme d'Orange compare ses épreuves et les confronte pour la validation, avant de faire remonter les conflits autour des mots concernés », explique Isabelle Josse.
Par ailleurs, l'algorithme utilisé permet la propagation des corrections : un mot correctement identifié verra ainsi ses caractères être appliqués à d'autres documents présentant les mêmes difficultés. « Les erreurs de l'OCR reposent beaucoup sur la mauvaise compréhension de caractères à cause d'une frappe particulière. Un imprimeur qui a ainsi frappé les caractères "i" et "n" très serrés "provoque" ainsi une mauvaise compréhension de l'OCR, qui identifie un "m" », détaille Arnaud Beaufort.
En croisant les données et les corrections, l'algorithme effectue un travail qu'il aurait été difficile de confier à une équipe entière, et qui facilitera les utilisations à venir des documents. « Par rapport à Wikisource, où les corrections étaient validées au cas par cas, par un modérateur, la plateforme est plus "détendue" : nous avons là 3 millions de documents en attente, et il ne faut pas forcément faire de la surqualité sur un seul. »
La BnF suit attentivement les premiers pas des utilisateurs, et apporte un soutien aux correcteurs, sous la forme d'un guide pratique ou d'aide technique pour la correction des césures ou des ligatures. Elle découvre également les usages possibles, comme la création d'un groupe par une documentaliste d'un lycée de Casablanca, « probablement pour un projet pédagogique ».
Gallica propose déjà une fonctionnalité pour lire l'OCR d'une page numérisée : d'ici quelques semaines, il sera même possible de mettre en vis-à-vis l'image numérisée et la transcription OCR, pour plus de facilité. Par ailleurs, les images et les OCR peuvent être téléchargés, et leurs usages sont libres et gratuits, dans la limite d'un but non commercial. La transcription OCR indique par ailleurs à l'intéressé le taux de fiabilité de la reconnaissance, calculé à partir des taux d'OCR de chaque mot. En attendant le 100 %...
Plus d'articles sur le même thème
































Autres articles de la rubrique Patrimoine
































Commenter cet article